Getting Started¶
Welcome to ell, the Language Model Programming Library. This guide will walk you through creating your first Language Model Program (LMP), exploring ell’s unique features, and leveraging its powerful versioning and visualization capabilities.
From Traditional API Calls to ell¶
Let’s start by comparing a traditional API call to ell’s approach. Here’s a simple example using the OpenAI chat completions API:
import openai
openai.api_key = "your-api-key-here"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Say hello to Sam Altman!"}
]
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=messages
)
print(response['choices'][0]['message']['content'])
Now, let’s see how we can achieve the same result using ell:
import ell
@ell.simple(model="gpt-4o")
def hello(name: str):
"""You are a helpful assistant.""" # System prompt
return f"Say hello to {name}!" # User prompt
greeting = hello("Sam Altman")
print(greeting)
ell simplifies prompting by encouraging you to define prompts as functional units. In this example, the hello function defines a system prompt via the docstring and a user prompt via the return string. Users of your prompt can then simply call the function with the defined arguments, rather than manually constructing the messages. This approach makes prompts more readable, maintainable, and reusable.
Understanding @ell.simple¶
The @ell.simple decorator is a key concept in ell. It transforms a regular Python function into a Language Model Program (LMP). Here’s what’s happening:
The function’s docstring becomes the system message.
The return value of the function becomes the user message.
The decorator handles the API call and returns the model’s response as a string.
This encapsulation allows for cleaner, more reusable code. You can now call your LMP like any other Python function.
Verbose Mode¶
To get more insight into what’s happening behind the scenes, you can enable verbose mode:
ell.init(verbose=True)
With verbose mode enabled, you’ll see detailed information about the inputs and outputs of your language model calls.
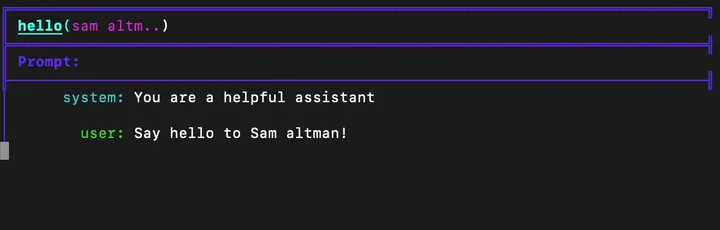
Alternative Message Formats¶
While the previous example used the docstring for the system message and the return value for the user message, ell offers more flexibility. You can explicitly define messages using ell.system, ell.user, and ell.assistant:
import ell
@ell.simple(model="gpt-4o")
def hello(name: str):
return [
ell.system("You are a helpful assistant."),
ell.user(f"Say hello to {name}!"),
ell.assistant("Hello! I'd be happy to greet Sam Altman."),
ell.user("Great! Now do it more enthusiastically.")
]
greeting = hello("Sam Altman")
print(greeting)
This approach allows you to construct more complex conversations within your LMP. Importantly, you’ll want to use this approach when you have a variable system prompt because python only allows you to have a static docstring.
Prompting as Language Model Programming¶
One of ell’s most powerful features is its treatment of prompts as programs rather than simple strings. This approach allows you to leverage the full power of Python in your prompt engineering. Let’s see how this works:
import ell
import random
def get_random_adjective():
adjectives = ["enthusiastic", "cheerful", "warm", "friendly"]
return random.choice(adjectives)
@ell.simple(model="gpt-4o")
def hello(name: str):
"""You are a helpful assistant."""
adjective = get_random_adjective()
return f"Say a {adjective} hello to {name}!"
greeting = hello("Sam Altman")
print(greeting)
In this example, our hello LMP depends on the get_random_adjective function. Each time hello is called, it generates a different adjective, creating dynamic, varied prompts.
Taking this concept further, LMPs can call other LMPs, allowing for more complex and powerful prompt engineering strategies. Let’s look at an example:
import ell
from typing import List
ell.init(verbose=True)
@ell.simple(model="gpt-4o-mini", temperature=1.0)
def generate_story_ideas(about : str):
"""You are an expert story ideator. Only answer in a single sentence."""
return f"Generate a story idea about {about}."
@ell.simple(model="gpt-4o-mini", temperature=1.0)
def write_a_draft_of_a_story(idea : str):
"""You are an adept story writer. The story should only be 3 paragraphs."""
return f"Write a story about {idea}."
@ell.simple(model="gpt-4o", temperature=0.1)
def choose_the_best_draft(drafts : List[str]):
"""You are an expert fiction editor."""
return f"Choose the best draft from the following list: {'\n'.join(drafts)}."
@ell.simple(model="gpt-4-turbo", temperature=0.2)
def write_a_really_good_story(about : str):
"""You are an expert novelist that writes in the style of Hemmingway. You write in lowercase."""
# Note: You can pass in api_params to control the language model call
# in the case n = 4 tells OpenAI to generate a batch of 4 outputs.
ideas = generate_story_ideas(about, api_params=(dict(n=4)))
drafts = [write_a_draft_of_a_story(idea) for idea in ideas]
best_draft = choose_the_best_draft(drafts)
return f"Make a final revision of this story in your voice: {best_draft}."
story = write_a_really_good_story("a dog")
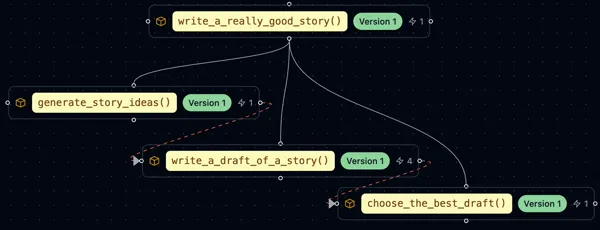
In this example, write_a_really_good_story is our main LMP that calls several other LMPs to produce a high-quality story. Here’s how it works:
First, it calls
generate_story_ideasto create four different story ideas about the given topic.Then, it uses
write_a_draft_of_a_storyto write a draft for each of these ideas.Next, it uses
choose_the_best_draftto select the best story from these drafts.Finally, it revises the best draft in the style of Hemingway.
This approach leverages test-time compute techniques, specifically Best-of-N (BoN) sampling. By generating multiple ideas and drafts, then selecting the best one, we increase the chances of producing a high-quality output. This strategy allows us to really leverage the most out of language models in several ways:
Diversity: By generating multiple ideas and drafts, we explore a broader space of possible outputs.
Quality Control: The selection step helps filter out lower-quality outputs.
Specialization: Each step is handled by a specialized LMP, allowing for more focused and effective prompts.
Iterative Improvement: The final revision step allows for further refinement of the chosen draft.
This compositional approach to prompt engineering enables us to break down complex tasks into smaller, more manageable steps. It also allows us to apply different strategies (like varying temperature or using different models) at each stage of the process, giving us fine-grained control over the output generation.
Storing and Versioning Your Prompts¶
ell provides powerful versioning capabilities for your LMPs. To enable this feature, add the following line near the beginning of your script:
ell.init(store='./logdir', autocommit=True, verbose=True)
This line sets up a store in the ./logdir directory and enables autocommit. ell will now store all your prompts and their versions in ./logdir/ell.db, along with a blob store for images.
Exploring Your Prompts with ell-studio¶
After running your script with versioning enabled, you can explore your prompts using ell-studio. In your terminal, run:
ell-studio --storage ./logdir
This command opens the ell-studio interface in your web browser. Here, you can visualize your LMPs, see their dependencies, and track changes over time.
Iterating and Auto-Committing¶
Let’s see how ell’s versioning works as we iterate on our hello LMP:
Version 1:
import ell
import random
ell.init(store='./logdir', autocommit=True)
def get_random_adjective():
adjectives = ["enthusiastic", "cheerful", "warm", "friendly"]
return random.choice(adjectives)
@ell.simple(model="gpt-4o")
def hello(name: str):
"""You are a helpful assistant."""
adjective = get_random_adjective()
return f"Say a {adjective} hello to {name}!"
greeting = hello("Sam Altman")
print(greeting)
After running this script, ell will generate an initial commit message like:
“Initial version of hello LMP with random adjective selection.”
Now, let’s modify our LMP:
Version 2:
import ell
import random
ell.init(store='./logdir', autocommit=True)
def get_random_adjective():
adjectives = ["enthusiastic", "cheerful", "warm", "friendly", "heartfelt", "sincere"]
return random.choice(adjectives)
def get_random_punctuation():
return random.choice(["!", "!!", "!!!"])
@ell.simple(model="gpt-4o")
def hello(name: str):
"""You are a helpful and expressive assistant."""
adjective = get_random_adjective()
punctuation = get_random_punctuation()
return f"Say a {adjective} hello to {name}{punctuation}"
greeting = hello("Sam Altman")
print(greeting)
Running this updated script will generate a new commit message:
“Updated hello LMP: Added more adjectives, introduced random punctuation, and modified system prompt.”
ell’s autocommit feature uses gpt-4o-mini to generate these commit messages automatically, providing a clear history of how your LMPs evolve.
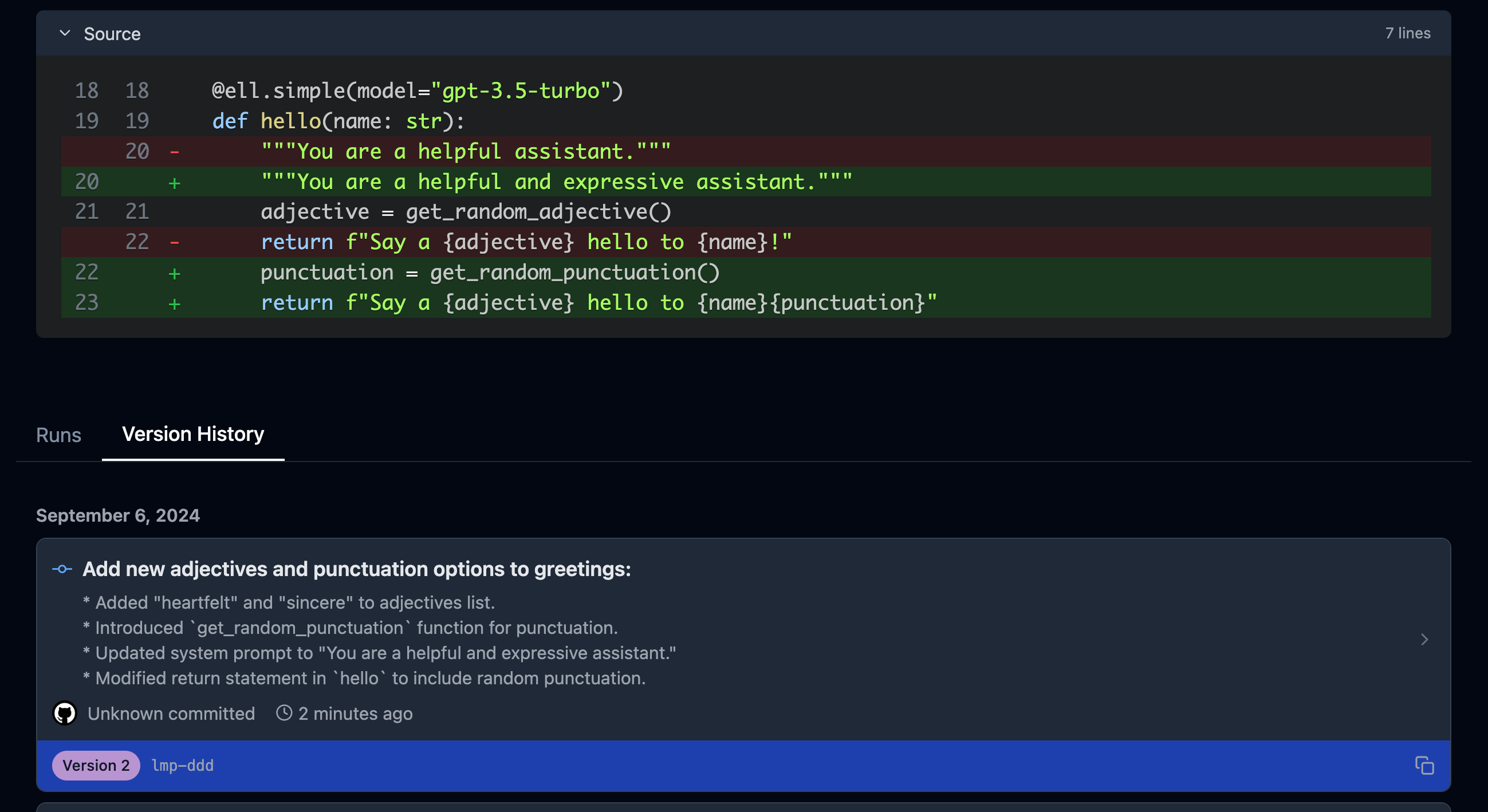
Comparing Outputs Across Versions¶
One of the powerful features of ell-studio is the ability to compare outputs of your LMPs across different versions. This helps you understand how changes in your code affect the language model’s responses.
For example, you can select the two versions of the hello LMP we created and compare their outputs:
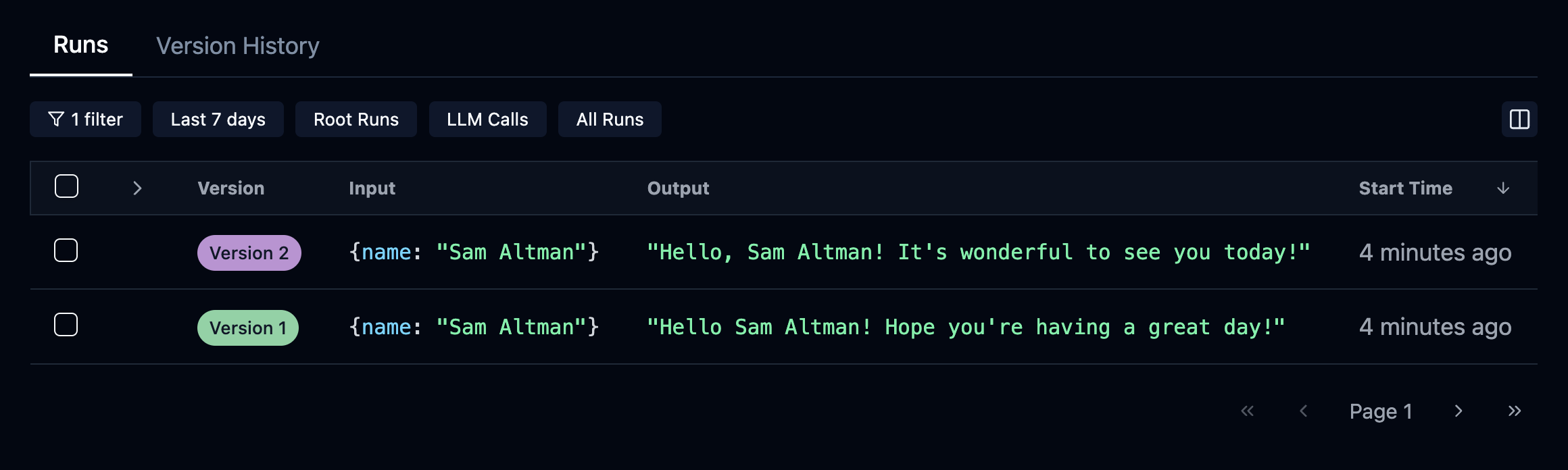
This comparison might show:
Version 1 output: “Here’s a warm hello to Sam Altman!” Version 2 output: “Here’s a heartfelt hello to Sam Altman!!!”
By visualizing these differences, you can quickly assess the impact of your changes and make informed decisions about your prompt engineering process.
What’s Next?¶
Now that you’ve created your first LMP, explored versioning, and learned about ell-studio, there’s much more to discover:
@ell.complex: For advanced use cases involving tool usage, structured outputs, and the full message API.Multimodal inputs and outputs: Work with images, videos, and audio in your LMPs.
API clients and models: Explore various language models and APIs supported by ell.
Designing effective Language Model Programs: Discover best practices for creating robust and efficient LMPs.
Tutorials: Check out in-depth tutorials for real-world applications of ell.